# 판다스의 series 데이터셋
# dictionary를 Series 데이터로 저장하기
import pandas as pd
dict_data = {'a':1,'b':2,'c':3}
sr = pd.Series(dict_data)
print(type(sr))
print(sr)
print(sr.index)
print(sr.values)
# 리스트를 시리즈 데이터로 저장
list_data = ['2019-01-02', 3.14, 'ABC', 100, True]
sr = pd.Series(list_data)
print(sr)
print(sr.index)
print(sr.values)
# tuple을 시리즈 데이터로 저장
tup_data = ('길동',"1990-01-01","남자",True)
sr = pd.Series(tup_data,index=["이름","생년월일","성별","학생여부"])
print(sr)
print(sr.index)
print(sr.values)
# 시리즈 데이터에 조회하기
# 원소 1개 선택
print(sr[0]) #첫번째 데이터
print(sr["이름"]) #인덱스명으로 조회
# 원소 여러개 선택
# 리스트의 리스트를 생성해야한다.
print(sr[[1,2]]) #1,2번 인덱스 데이터 조회
print(sr[["이름","성별"]])
print(sr[[0,3]])
print(sr[["이름","학생여부"]])
# 원소 여러개 선택. 범위 지정
print(sr[1:2]) #1번 인덱스부터 2번 앞 인덱스까지
print(sr["이름":"성별"]) #인덱스 순서대로 전부 다 조회된다
#데이터 프레임 생성하기
import pandas as pd
dict_data = {'c0':[1,2,3], 'c1':[4,5,6],\
'c2':[7,8,9], 'c3':[10,11,12],'c4':[13,14,15]}
df = pd.DataFrame(dict_data)
print(df)
print(type(df))
# 행, 열의 인덱스명을 지정하기
df = pd.DataFrame([[15,"남","서울중"],[17,"여","서울고"]],
index=['길동','길순'], #행의 이름
columns=["나이","성별","학교"]) #열의 이름
print(df)
print(type(df))
print(df.index)
print(df.columns)
# 나이=>연령, 성별=>남녀, 학교=>소속
df.rename(columns={"나이":"연령","성별":"남녀","학교":"소속"})
print(df)
print(df.index)
print(df.columns)
# 인덱스명 변경하기
df.rename(index={"길동":"학생1","길순":"학생2"},inplace=True)
print(df)
print(df.index)
print(df.columns)
exam_data = {'수학' : [90,80,70], '영어':[98,89,95],
'음악' : [85,95,100], '체육': [100,90,90]}
# exam_data 인덱스가 홍길동, 이몽룡, 김삿갓으로 나오도록 dataframe 객체 생성하기
df = pd.DataFrame(exam_data, index=['홍길동','이몽룡','김삿갓'])
print(df)
# 평균 구하기 : mean()
print(df.mean())
print(df["수학"].mean())
# 중앙값 구하기 : median()
print(df.median())
print(df["수학"].median())
# 최대값 구하기 : max()
print(df.max())
# 최대값 구하기 : max()
print(df.min())
# 표준편차 : std()
print(df.std())
# 상관계수 : corr()
print(df.corr())
print(df[["수학","영어"]].corr())
# 한개 행 삭제하기
# df2 = df로 하면 복사되는 것이 아니라 df2가 df의 또 다른 이름이 된다.
# df2 = df 얕은 복사
# df2 = df[:] 깊은 복사
df2 = df[:] #df 데이터의 컬럼 처음부터 끝까지의 정보를 df2에 입력한다.
print(df2)
df2.drop("홍길동", inplace=True)
print(df2)
# 여러개 행 삭제하기
df3 = df[:]
print(df3)
df3.drop(["홍길동","이몽룡"],inplace=True)
print(df3)
print(df)

# copy 함수 이용해서 객체 복사 (깊은 복사)
df4 = df.copy()
df4.drop("홍길동",inplace=True)
print(df4)
print(df)
# 컬럼 삭제
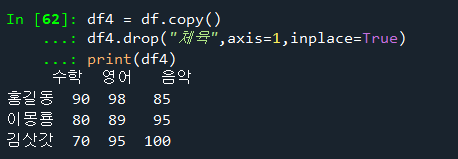
df4 = df.copy()
df4.drop("체육",axis=1,inplace=True)
print(df4)
# 여러개의 컬럼 삭제
df4 = df.copy()
df4.drop(["체육","음악"],axis=1,inplace=True)
print(df4)

# 행 선택하기
exam_data = {'수학': [90,80,70], "영어":[98,89,95],
'음악': [85,95,100], "체육":[100,90,95]}
df = pd.DataFrame(exam_data, index=["홍길동","이몽룡","김삿갓"])
# 열 선택하기
print(df["수학"])
# 행(row) 선택하기
# loc[인덱스이름] : 인덱스 한개 선택하기
# iloc[인덱스의순서값] : 0부터 시작하는 순서의 값
row1 = df.loc["홍길동"]
row1
row2 = df.iloc[0]
row2
df = pd.DataFrame({"A":[1,4,7],"B":[2,5,8],"C":[3,6,9]})
print(df)
# iloc 이용하여 행 조회하기
print(df.iloc[0])
print(df.iloc[1])
print(df.iloc[2])
# loc 이용하여 행 조회하기
print(df.loc[0])
print(df.loc[1])
print(df.loc[2])
df = pd.DataFrame(data=([[1,2,3],[4,5,6],[7,8,9]]),
index=[2,"A",4],columns=[51,52,54])
print(df)
print(df.iloc[2])
print(df.loc[2])
print(df.iloc[4]) # 오류발생 4번(5번째) 인덱스가 없음
print(df.loc[4]) # 세번째 행의 값 출력
#
exam_data = {'수학': [90,80,70], "영어":[98,89,95],
'음악': [85,95,100], "체육":[100,90,95]}
df = pd.DataFrame(exam_data, index=["홍길동","이몽룡","김삿갓"])
# 이몽룡 점수 출력하기
# loc
print(df.loc["이몽룡"])
# iloc
print(df.iloc[1])
# 홍길동,이몽룡 점수 출력하기
# loc
print(df.loc[["홍길동","이몽룡"]])
# iloc
print(df.iloc[0:2])
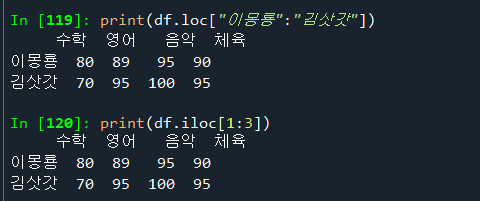
# 이몽룡,김삿갓 점수 출력하기. 범위 기준
print(df.loc["이몽룡":"김삿갓"])
print(df.iloc[1:3])
# 수학 점수 데이터만 math1 변수에 저장
math1 = df["수학"]
print(math1)
print(type(math1))
# 영어 점수 데이터만 eng1 변수에 저장하기
# eng1 출력하기
eng1 = df["영어"]
print(eng1)
print(type(eng1))
# 음악, 체육 점수 데이터만 mu_gy 변수에 저장하기
mu_gy = df[["음악","체육"]]
print(mu_gy)
# df 데이터프레임의 부분 프레임
math2 = df[["수학"]]
print(math2)
print(type(math2))
'Python' 카테고리의 다른 글
| Python - json 파일 읽기 (0) | 2021.06.22 |
|---|---|
| Python - 판다스 xlsx 불러오기, 저장하기 연습문제 (infile,outfile) (0) | 2021.06.22 |
| Python - xlsx,xls 파일 읽기 [openpyxl, pandas] (0) | 2021.06.21 |
| Python - Database 연습문제 (0) | 2021.06.21 |
| Python - Database (0) | 2021.06.18 |