'''
비트코인 시세 예측하기
https://www.blockchain.com/charts/market-price
-> CSV 포맷으로 다운로드 받기
시계열 데이터 : 연속적인 시간에 따라 다르게 측정되는 데이터.
ARIMA 모델 => Statsmodel
AR : 과거 정보를 사용
MA : 이전 정보의 오차를 현재 상태로 추론
'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
### market-price.csv 파일을 로드 -> bitcoin_df에 저장
file_path = 'market-price.csv'
bitcoin_df = pd.read_csv(file_path)
bitcoin_df.info()
bitcoin_df.head()
bitcoin_df = pd.read_csv(file_path, names=['day','price'],header=0)
bitcoin_df.info()
bitcoin_df.head()
bitcoin_df.shape
# day 컬럼을 시계열 피처로 변환하기
bitcoin_df['day'] = pd.to_datetime(bitcoin_df["day"])
bitcoin_df.info()
bitcoin_df.head()
bitcoin_df.describe()
bitcoin_df.set_index('day',inplace=True)
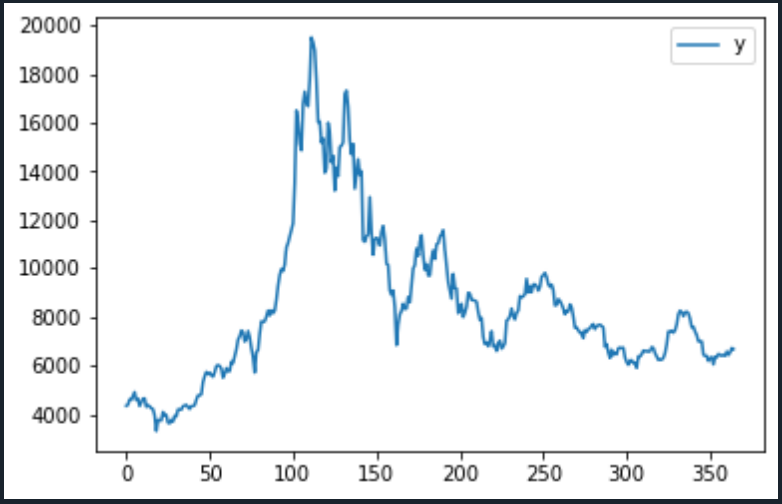
# 일자별 가격을 시각화하기
bitcoin_df.plot()
plot.show()
# ARIMA 모델 학습
'''
order = (2,1,2)
2 => AR. 2번째 과거까지
1 => 차분 정보. 현재 상태값 - 바로 이전의 상태 뺀 값
시계열 데이터의 불규칙성을 보정
2 => MA. 2번째 과거 정보를 조회
'''
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(bitcoin_df.price.values, order=(2,1,2))
model_fit = model.fit(trend='C', full_output=True, disp=True)
fig = model_fit.plot_predict() #학습 데이터에 대한 예측 결과를 그래프로 그리기
residuals = pd.DataFrame(model_fit.resid) #잔차의 변동을 시각화
residuals.plot()
# 실제 데이터와의 비교
# 이후 5일 정보를 예측하기
forecast_data = model_fit.forecast(steps=5)
'''
1번 배열 : 예측값. 5일치 예측값
2번 배열 : 표준오차. 5일치 예측값
3번 배열 : 5개의 배열
[얘측 데이터 하한값]
'''
forecast_data # 예측데이터
# 실데이터 읽어오기
test_file_path = 'market-price-test.csv'
bitcoin_test_df = pd.read_csv(test_file_path, names=['ds','y'],header=0) #실제 데이터
bitcoin_test_df['y']
bitcoin_test_df['y'].values
# 예측값 pred_y 변수에 리스트로 저장하기
pred_y = forecast_data[0].tolist()
pred_y
# 실제값을 test_y 변수에 리스트로 저장하기
test_y = bitcoin_test_df['y'].values
test_y
pred_y_lower = [] # 최소 예측값들
pred_y_upper = [] # 최대 예측값들
for low_up in forecast_data[2] :
pred_y_lower.append(low_up[0])
pred_y_upper.append(low_up[1])
pred_y_lower
pred_y_upper
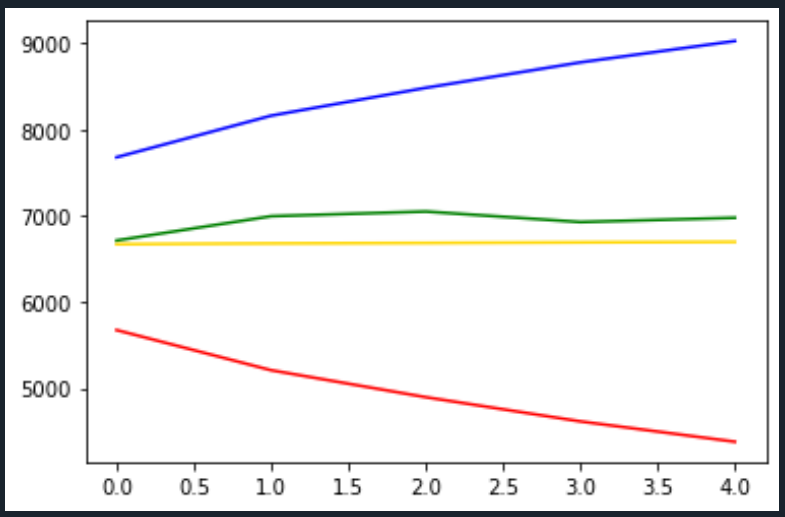
# 시각화하기
plt.plot(pred_y, color='gold')
plt.plot(test_y, color='green')
plt.plot(pred_y_lower, color='red')
plt.plot(pred_y_upper, color='blue')
#
plt.plot(pred_y, color='gold') # 예측값
plt.plot(test_y, color='green') # 실제값
'''
시계열 데이터 분석을 위한 모델
AR(자기회귀분석)
현재 값 과거의 값을 관꼐
AR(n) : n 이전의 시점
MA(이동 평균 모델)
과거와 현재의 오차의 관계
ARMA(자기 회귀 이동 평균 모델)
ARIMA (자기 회귀 누적 이동 평균 모델)
-> 현재와 추세간의 관계 정의
-> ARMA 방식은 불규칙적인 시계열데이터 분석 예측하기 어려움
-> 보안하기 위해 ARIMA 방식
ARIMA(p,d,q)
p : AR 모형 차수
d : 차분
q : MA 모형 차수
'''
'''
Facebook Prophet 활용하여 시게열 데이터 분석하기
Anaconda Prompt에서 아래 실행
=> conda install -c conda-forge fbprophet
pip install pystan --upgrade <- 콘솔창에 입력
'''
from fbprophet import Prophet
bitcoin_df = pd.read_csv(file_path, names=['ds','y'], header=0)
bitcoin_df.info()
# Prophet : Facebook
prophet = Prophet(seasonality_mode = "multiplicative",
yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=True,
changepoint_prior_scale=0.5)
# 학습하기
prophet.fit(bitcoin_df)
# 5일 앞을 예측하기 d = day / 5 = 5일
future_data = prophet.make_future_dataframe(periods=5,freq='d')
forecast_data = prophet.predict(future_data)
forecast_data
# 예측된 데이터의 날짜, 예측값, 최소예측값, 최대예측값
forecast_data[['ds','yhat','yhat_lower','yhat_upper']].tail(5)
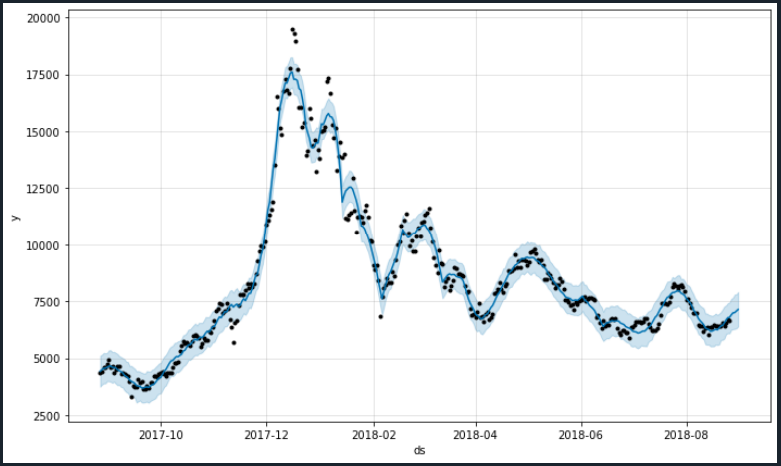
# 결과의 시각화
# 검은점 : 실데이터
# 파란색 : 예측값
fig1 = prophet.plot(forecast_data)
fig2 = prophet.plot_components(forecast_data)
# 실제 가격과 예측 가격 간의 차이 분석 => 성능
y = bitcoin_df.y.values[5:] #실제 데이터. 첫 5일 제외. 실데이터
y_pred = forecast_data.yhat.values[5:-5]
# r2score, RSME 값을 출력하기
from sklearn.metrics import mean_squared_error, r2_score
from math import sqrt
r2 = r2_score(y, y_pred)
r2
rmse = sqrt(mean_squared_error(y,y_pred))
rmse
# 실제 데이터와 비교
test_file_path = 'market-price-test.csv'
# 실데이터 정보
bitcoin_test_df = pd.read_csv(test_file_path,names=['ds','y'],header=0)
y = bitcoin_test_df.y.values
y
y_pred = forecast_data.yhat.values[-5:]
y_pred
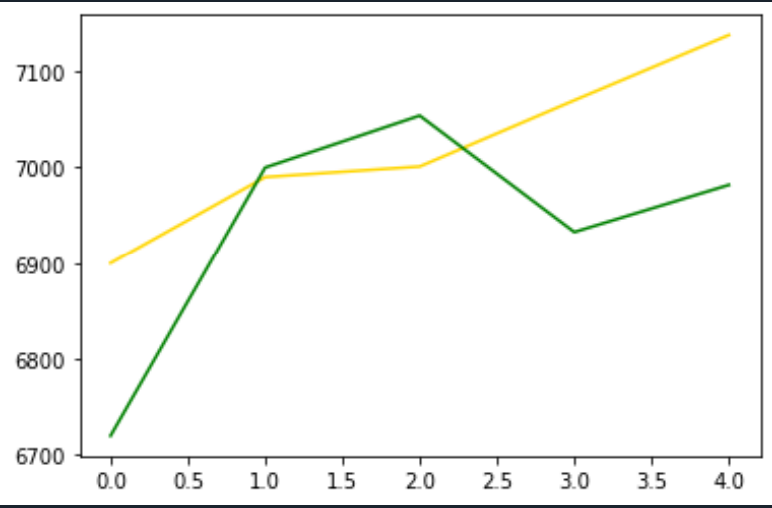
plt.plot(y_pred,color='gold')
plt.plot(y,color='green')
'Python' 카테고리의 다른 글
| Python - 카카오맵 크롤링(with Selenium) (0) | 2021.07.26 |
|---|---|
| Python - 홈페이지 탐색(with Selenium) (0) | 2021.07.23 |
| Python - 군집분석 (0) | 2021.07.20 |
| Python - 의사결정나무(Decision Tree) (0) | 2021.07.16 |
| Python - SVM(서포트 벡터 머신) (0) | 2021.07.16 |



