'''
##### 크롤링으로 데이터 가져오기
##### wordcloud 그래프로 시각화하기
pip install pytagcloud pygame simplejson
ㄴ 아래 세가지를 합쳐서 입력
1. pip install pytagcloud => wordcloud 그래프
2. pip install pygame
3. pip install simplejson
##### 형태소 분석 : konlpy 모듈 필요
** 윈도우 사용시 셋팅 필수 !
pip install konlpy
https://www.lfd.uci.edu/~gohlke/pythonlibs/#jpype
파이썬의 버전 확인
anaconda prompt > python --version 입력 > 3.8.8
jpype 사이트에서
JPype1-1.1.2-cp38-cp38-win_amd64.whl 파일 다운 받기
JPype1-1.1.2-cp38-cp38-win_amd64.whl
C:\Users\82103 이곳에 저장
anaconda prompt > pip install JPype1-1.1.2-cp38-cp38-win_amd64.whl 입력
설정 성공
'''
from konlpy.tag import Okt
okt = Okt()
print(okt.morphs(u'단독입찰보다 복수입찰의 경우'))
### 나무위키 사이트로 접속하여 데이터 가져오기
from selenium import webdriver
import re
# chromedirver.exe 파일의 위치
path = "C:/User/Pyth/workspace/chromedriver"
# 크롤링할 사이트 주소
source_url = "https://namu.wiki/RecentChanges"
driver = webdriver.Chrome(path)
driver.get(source_url)
a_data = driver.find_elements_by_css_selector("table tr td a")
print(len(a_data))
page_urls = []
cnt = 0
# a_data : a 태그들의 모임.
# a : <a href = ....>문자열</a>
# a 태그 : 문자열을 클릭하면 href 속성의 값으로 현재 브라우저 페이지가 변경됨
# : href 속성의 값으로 연결하여, 브라우저 페이지에 표시됨
for a in a_data :
# a 태그의 속성 중 href 속성이 없는 경우
if a.get_attribute('href') == None :
continue # 다음
page_url = a.get_attribute('href')
if 'png' not in page_url:
page_urls.append(page_url)
cnt += 1
if cnt > 10 :
break
# 중복 url을 제거합니다.
# set(page_urls) : 중복된 url 정보가 한개만 남는다.
page_urls = list(set(page_urls))
for page in page_urls[:5]:
print(page)
print("*************************")
print(page_urls)
# 크롤링에 사용된 브라우저를 종료합니다.
driver.close()
# page_urls : 크롤링 대상이 되는 url 정보 저장
import pandas as pd
from bs4 import BeautifulSoup
columns = ["title","category","content_txt"]
df = pd.DataFrame(columns=columns)
df
for page_url in page_urls:
driver = webdriver.Chrome(path) #크롬브라우저 로드
driver.get(page_url) #크롬브라우저 페이지 로드
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
# contents_table : article 이름의 태그를 선택하여 저장
contents_table = soup.find(name="article")
title = contents_table.find_all("h1")[0]
# contents_table 태그의 하위 태그들 중 ul 태그의 갯수가 0보다 크면
if len(contents_table.find_all("ul")) > 0 :
# category : contents_table 태그 하위 태그 중 첫번째 ul태그
category = contents_table.find_all("ul")[0]
else :
category = None
# attrs : 속성
content_paragraphs = contents_table.find_all(name="div",attrs={"class":"wiki-paragraph"})
content_corpus_list = []
if title is not None:
row_title = title.text.replace("\n", " ")
else :
row_title = ""
if content_paragraphs is not None :
for paragraphs in content_paragraphs:
if paragraphs is not None :
content_corpus_list.append(paragraphs.text.replace("\n"," "))
else :
content_corpus_list.append("")
else :
content_corpus_list.append("")
if category is not None:
row_category = category.text.replace("\n"," ")
else :
row_category = ""
row = [row_title, row_category, "".join(content_corpus_list)]
series = pd.Series(row, index=df.columns)
df = df.append(series, ignore_index=True)
driver.close()
### for 구문
df.head()
df.info()
def text_cleaning(text):
hangul = re.compile('[^ ㄱ-ㅣ 가-힣]+')
result = hangul.sub('',text)
return result
df['title'] = df['title'].apply(lambda x: text_cleaning(x))
df['category'] = df['category'].apply(lambda x: text_cleaning(x))
df['content_txt'] = df['content_txt'].apply(lambda x: text_cleaning(x))
df.head(5)
print(text_cleaning("漢자는 복잡하고, 한글은 smart하고 English ...11111"))
# df : 나무위키에서 수집한 텍스트 데이터 중 한글만 저장하고 있는 데이터 프레임 객체
# konlpy의 형태소 분석기 모듈을 이용하여 단어를 추출하기
from konlpy.tag import Okt
from collections import Counter
nouns_tagger = Okt()
# 각 피처마다 말뭉치를 생성합니다.
title_corpus = "".join(df['title'].tolist())
category_corpus = "".join(df['category'].tolist())
content_corpus = "".join(df['content_txt'].tolist())
title_corpus
category_corpus
content_corpus
nouns = nouns_tagger.nouns(content_corpus)
nouns[:5]
# 각 단어들의 빈도수 계산
count = Counter(nouns)
count
# 한글자 단어들은 제거하기
# x : 단어
# count[x] : 단어빈도수
remove_char_counter = Counter({x :count[x] for x in count if len(x)>1})
remove_char_counter
# 불용어 제거하기
# 불용어 파일 읽기
korean_stopwords = "korean_stopwords.txt"
with open(korean_stopwords, encoding='utf8') as f :
stopwords = f.readlines()
stopwords = [x.strip() for x in stopwords]
stopwords[:10]
# remove_char_counter 데이터에서 불용어를 제거합니다.
remove_char_counter = Counter({x:remove_char_counter[x] for x in remove_char_counter if x not in stopwords})
print(remove_char_counter)
'''
워드 클라우드 시각화
한글 출력을 위한 폰트 설정하기
폰트 다운로드 :
http://hangeul.naver.com/webfont/NanumGothic/NanumGothic.ttf
pip install pytagcloud
NanumGothic.ttf 다운받기
C:\User\Pyth\Lib\site-packages\pytagcloud\fonts에 저장하기
fonts.json 파일에 아래 내용 추가
{
"name":"Nanumgothic",
"ttf":"NanumGothic.ttf"
'web'
}
'''
# remove_char_counter : 단어의 빈도수 저장
# : 단어 길이가 두개 이상인 단어
# : 불용어 제거
# most_common(40) : 가장 많이 사용된 단어 40개만 저장
import pytagcloud
ranked_tags = remove_char_counter.most_common(40)
ranked_tags
# 단어 구름 시각화에 표시될 내용
# fontname = 'NanumGothic' : 한글 표시가 가능한 폰트여야 함
taglist = pytagcloud.make_tags(ranked_tags, maxsize=80)
pytagcloud.create_tag_image(taglist,'wordcloud.jpg',size=(900,600),fontname="NanumGothic",rectangular=False)
taglist
# title 부분을 단어 구름으로 시각화 하기
nouns = nouns_tagger.nouns(title_corpus)
nouns[:5]
count = Counter(nouns)
count
remove_char_counter = Counter({x :count[x] for x in count if len(x)>1})
remove_char_counter
korean_stopwords = "korean_stopwords.txt"
with open(korean_stopwords, encoding='utf8') as f :
stopwords = f.readlines()
stopwords = [x.strip() for x in stopwords]
stopwords[:10]
remove_char_counter = Counter({x:remove_char_counter[x] for x in remove_char_counter if x not in stopwords})
print(remove_char_counter)
ranked_tags = remove_char_counter.most_common(40)
ranked_tags
taglist = pytagcloud.make_tags(ranked_tags, maxsize=80)
pytagcloud.create_tag_image(taglist,'titlecloud.jpg',size=(900,600),fontname="NanumGothic",rectangular=False)
taglist
# category 부분을 단어 구름으로 시각화 하기
nouns = nouns_tagger.nouns(category_corpus)
nouns[:5]
count = Counter(nouns)
count
remove_char_counter = Counter({x :count[x] for x in count if len(x)>1})
remove_char_counter
korean_stopwords = "korean_stopwords.txt"
with open(korean_stopwords, encoding='utf8') as f :
stopwords = f.readlines()
stopwords = [x.strip() for x in stopwords]
stopwords[:10]
remove_char_counter = Counter({x:remove_char_counter[x] for x in remove_char_counter if x not in stopwords})
print(remove_char_counter)
ranked_tags = remove_char_counter.most_common(40)
ranked_tags
taglist = pytagcloud.make_tags(ranked_tags, maxsize=80)
pytagcloud.create_tag_image(taglist,'categorycloud.jpg',size=(900,600),fontname="NanumGothic",rectangular=False)
taglist
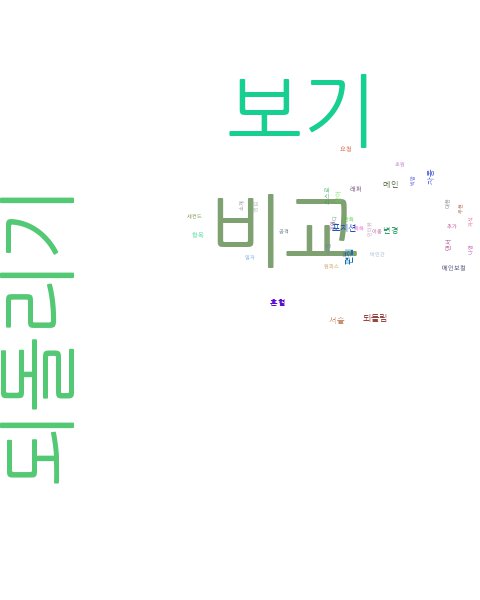
# 생성된 이미지를 바로 콘솔 창에 출력해주는 모듈
from IPython.display import Image
Image(filename='wordcloud.jpg')
Image(filename='titlecloud.jpg')
Image(filename='categorycloud.jpg')


'Python' 카테고리의 다른 글
| Python - 회귀분석(Regression) (0) | 2021.07.15 |
|---|---|
| Python - 서울시 CCTV수를 파악해서 시각화하기 (산점도, 회귀선) (0) | 2021.07.14 |
| Python - 웹크롤링 (BeautifulSoup/ Selenium) (0) | 2021.07.06 |
| Python - 변수저장, 데이터프레임 필터(조회기능), 데이터프레임 병합 (0) | 2021.07.05 |
| Python - 결측값처리 (0) | 2021.07.02 |


