KINESIS DATA STREAM
Kinesis Producer
(생략)
Kinesis Consumer - Classic
* Kinesis SDK
* Kinesis Client Library (KCL)
* Kinesis Connector Library
* 3rd party libraries : Spark, Kafak...
* Kinesis firehose
* AWS lambda
Kinesis Consumer SDK - GetRecords
* Classic Kinesis - Records are polled by consumers from a shard
* Each shard has 2 MB total aggregate throughput
* GetRecords returns up to 10MB of data (then throttle for 5 secods) or up to 10000 records
* Maximum of GetRecords API calls per shard per second = 200ms latency

Kinesis Client Library (KCL)
* java-first library (but, Golang, Python, Node, ...)
* Read record from kinesis produced with the KPL
* Checkpointing feature to resume progress
* DynamoDB for coordination
* Record processors will process the data
* ExpiredIteratorException

Kinesis Connector Library
* Older Java Library
* Write data to
- S3, DynamoDB, Redshfit, Opensearch
* Kinesis Firehose replaces the Connector Library for a few of these targets, lambda for the others

AWS lambda sourcing from Kinesis
* AWS lambda can source records from Kinesis Data Streams
* Lambda consumer has a library to de-aggregate record from the KPL
* Lambda can be used to run lightweight ETL to
- S3, DynamoDB, Redshift, Opensearch
* Lambda can be used to trigger notifictions/send emails in real time
AWS Kinesis Enhanced Fan-Out
AWS Kinesis Enhanced Fan-Out은 Amazon Kinesis Data Streams에서 데이터를 처리하고 소비하는 방법 중 하나입니다. Amazon Kinesis Data Streams는 대량의 실시간 데이터 스트림을 처리하기 위한 서비스로, 여러 응용 프로그램이 데이터를 동시에 읽고 처리할 수 있도록 지원합니다. Enhanced Fan-Out은 Kinesis Data Streams의 스트림에서 데이터를 효율적으로 소비하는 방법 중 하나로, 기존의 Shard Iterator를 사용하는 기본 소비 방식보다 향상된 성능을 제공합니다.
Enhanced Fan-Out을 사용하면 여러 소비자(또는 응용 프로그램)가 동일한 데이터 스트림의 다른 파티션을 병렬로 처리할 수 있습니다. 일반적인 Kinesis 소비 방법에서는 각 소비자가 독립적으로 자신의 Shard Iterator를 사용하여 데이터를 읽어오지만, Enhanced Fan-Out에서는 미리 계산된 레코드 플로우에 따라 여러 소비자가 데이터를 병렬로 소비할 수 있습니다.
Enhanced Fan-Out을 사용하면 다음과 같은 이점이 있습니다:
1. 더 높은 처리량: Enhanced Fan-Out을 사용하면 각 소비자가 동시에 여러 파티션에서 데이터를 읽을 수 있으므로 처리량이 증가합니다.
2. 낮은 지연 시간: 데이터 스트림의 레코드를 소비하는 여러 소비자 간에 병렬 처리가 가능하므로 지연 시간이 감소합니다.
3. 스케일링: 여러 소비자를 추가하여 시스템을 쉽게 확장할 수 있습니다.
Enhanced Fan-Out은 Kinesis Data Streams의 API를 통해 활성화하며, 사용자는 Enhanced Fan-Out을 지원하는 소비자 애플리케이션을 작성해야 합니다. Enhanced Fan-Out을 사용하면 더 효율적인 데이터 스트림 처리 및 실시간 분석이 가능해지므로, 대규모 데이터 소스에서 발생하는 대용량 실시간 데이터에 대한 요구를 충족시키는 데 도움이 됩니다.
Kinesis Scaling
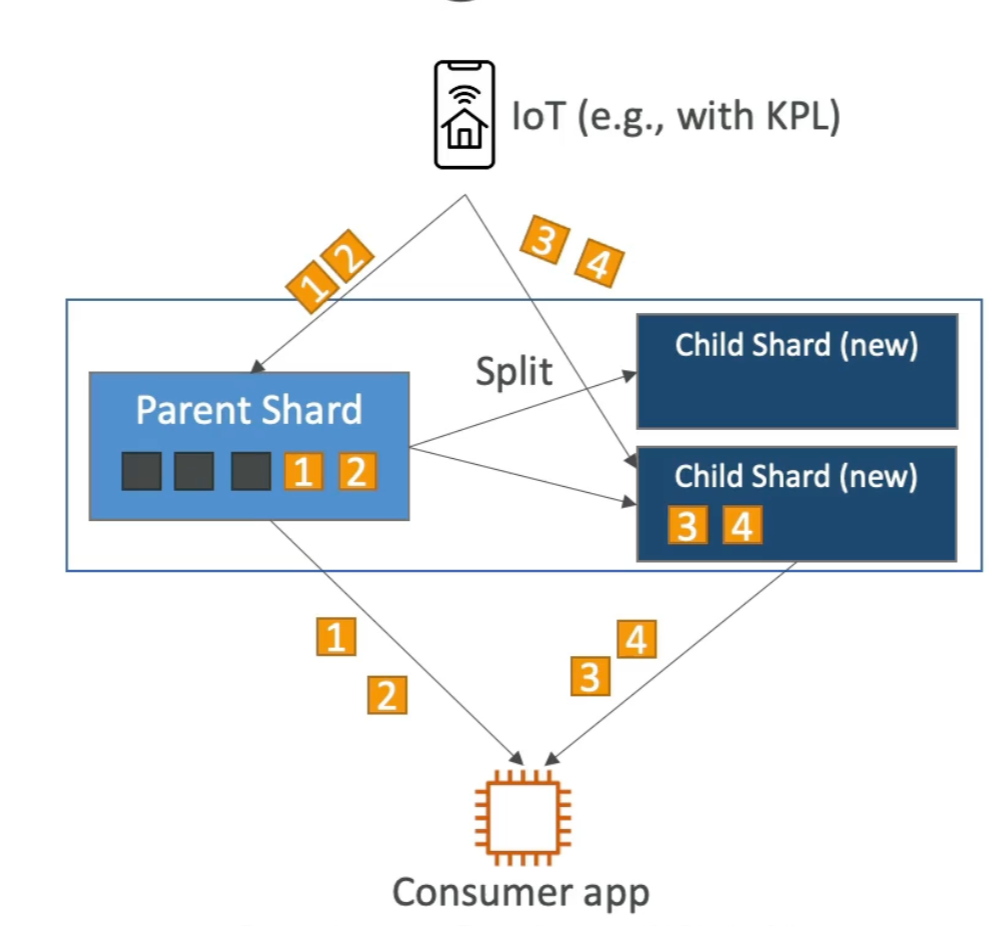
* Kinesis Operations - Adding Shards
> Also called "shard splitting"
> Can be sued to increase the stream capacity (1 mb/s data in per shard)
> Can be used to divide a "hot shard"
> The old shard is closed and will be deleted once the data is expired

* Kinesis Operation - Merging Shards
> Decrease the stream capacity and save costs
> Can be used to group two shards with low traffic
> Old shards are closed and deleted based on data expiration

* Out of order records after resharding
> After a reshard, you can read from child shards
> However, data you haven't read yet colud still be in the parent
> If you start reading the child before completing reading the parent, you colud read data for a particular has key out of order
* Auto Scaling
> The API call to change the number of shard is UpdateShardCount
> AWS Lambda
* Kinesis Scaling Limitaion
> cannot be done in parallel. Plan capacity in advance **
> resharding operation
> for 1000 shards, 30k seconds
Handling Duplicates
* Handling Duplicates For Producers
> Producers retires can create duplicates due to network timeouts
> Although the two records have identical data, they also have unique sequnce numbers
> Fix : embed unqiue record ID in the data to de-duplicate on the consumer side

* Handling Duplicates For Consumers
> Consumer retires can make your application read the same date twice
> Consumer retires happen when record procesors restart:
(1) A worker terminates unexpectedly
(2) Worker instances are added or removed
(3) Shards are merged or split
(4) The application is deployed
Fixes:
(1) Make your consumer application idempotent
(2) If the final destination can handle duplicates, it's recommended to do it there
* Kinesis Security
> Control access / authorization using IAM policies
> Encryption in flight using HTTPS endpoints
> Encryption at rest using KMS
> Client side encryption must be manually implemented
> VPC endpoints avaiable for Kinesis to access within VPC
B. Create a customer master key (CMK) in AWS KMS. Assign the CMK an alias. Enable server-side encryption on the Kinesis data stream using the CMK alias as the KMS master key.
KINESIS DATA FIREHOSE

> Fully Managed service
> Near Real Time (Buffer based on time and size, optionally can be disabled)
> Load data into Redshift / Amazon S3 / OpenSearch / Splunk
> Automatic Scaling
> Supports many data formats
> Data Conversions from Json to Parquet / ORC (only for S3)
> Data Transformation through AWS Lambda (ex. csv -> json)
> Support compression when target is Amazon S3 (Gzip, zip and snappy)
> Only Gzip is the data if further loaded into Redshift
> Pay for the amount of data going through Firehose
> Spark / KCL do not read from KDF

* Firehose Buffer Sizing
> Firehose accumulates records in a buffer
> The buffer is flushed based on time and size rules
Kinesis Data Streams vs Kinesis Data Firehose
| Kinesis Data Streams | Firehose |
| > Going to write custom code > Real time (~200ms latency for classic, ~70ms latency for enhanced fan-out) > Must manage scaling (shard splitting, merging) > Data storage for 1 to 365 days, replay capability, multi consumers > Use with lambda to insert data in real-time to OpenSearch |
>Fully Managed, send to S3, Splunk, Redshift, Opensearch >Serverless data transformation with lambda >Near realtime >Automated Scaling |
* Cloudwatch Logs subscriptions Filters
You can stream