# 주제 : 데이터로 살펴보는 학생의 학습 성공/실패 요소
## 실습 가이드
1. 데이터를 다운로드하여 Colab에 불러옵니다.
2. 필요한 라이브러리는 모두 코드로 작성되어 있습니다.
3. 코드는 위에서부터 아래로 순서대로 실행합니다.
## 데이터 소개
- 이번 주제는 xAPI-Edu-Data 데이터셋을 사용합니다.
- 다음 1개의 csv 파일을 사용합니다.
xAPI-Edu-Data.csv
- 각 파일의 컬럼은 아래와 같습니다.
gender: 학생의 성별 (M: 남성, F: 여성)
NationaliTy: 학생의 국적
PlaceofBirth: 학생이 태어난 국가
StageID: 학생이 다니는 학교 (초,중,고)
GradeID: 학생이 속한 성적 등급
SectionID: 학생이 속한 반 이름
Topic: 수강한 과목
Semester: 수강한 학기 (1학기/2학기)
Relation: 주 보호자와 학생의 관계
raisedhands: 학생이 수업 중 손을 든 횟수
VisITedResources: 학생이 과목 공지를 확인한 횟수
Discussion: 학생이 토론 그룹에 참여한 횟수
ParentAnsweringSurvey: 부모가 학교 설문에 참여했는지 여부
ParentschoolSatisfaction: 부모가 학교에 만족했는지 여부
StudentAbscenceDays: 학생의 결석 횟수 (7회 이상/미만)
Class: 학생의 성적 등급 (L: 낮음, M: 보통, H: 높음)
- 데이터 출처: https://www.kaggle.com/aljarah/xAPI-Edu-Data
## 최종 목표
- 연구용 Tabular 데이터의 이해
- 데이터 시각화를 통한 인사이트 습득 방법의 이해
- Scikit-learn 기반의 모델 학습 방법 습득
- Logistic Regression, XGBoost 기반의 모델 학습 방법 습득
- 학습된 모델의 평가 방법 및 시각화 방법 습득
### Step 1. 데이터셋 준비하기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
### 문제 1. Colab Notebook에 Kaggle API 세팅하기
import os
# os.environ을 이용하여 Kaggle API Username, Key 세팅하기
# 캐글 - account - Create New API Token - Jason view 파일을 메모장으로 열기
os.environ["KAGGLE_USERNAME"] = 'jmsu5270'
os.environ["KAGGLE_KEY"] = '55175f50d3fab35dea43d1c5f4618359'
### 문제 2. 데이터 다운로드 및 압축 해제하기
# Linux 명령어로 Kaggle API를 이용하여 데이터셋 다운로드하기 (!kaggle ~)
# Linux 명령어로 압축 해제하기
# Copy API command 로 복사하고 !를 앞에 입력하고 붙여넣기
!kaggle datasets download -d aljarah/xAPI-Edu-Data
!unzip '*.zip'
### 문제 3. Pandas 라이브러리로 csv파일 `읽어들이기`
# pd.read_csv()로 csv파일 읽어들이기
df = pd.read_csv('xAPI-Edu-Data.csv')
## Step 2. EDA 및 데이터 기초 통계 분석
# DataFrame에서 제공하는 메소드를 이용하여 컬럼 분석하기 (head(), info(), describe())
df.head()

df.info()

df.columns

df['gender'].value_counts()

df['NationalITy'].value_counts()

### 문제 5. 수치형 데이터의 히스토그램 그리기
# seaborn의 histplot, jointplot, pairplot을 이용해 히스토그램 그리기
sns.histplot(x='raisedhands',data=df,hue='Class',hue_order=['L','M','H'],kde=True)

sns.histplot(x='VisITedResources',data=df,hue='Class',hue_order=['L','M','H'],kde=True)

sns.histplot(x='AnnouncementsView',data=df,hue='Class',hue_order=['L','M','H'],kde=True)

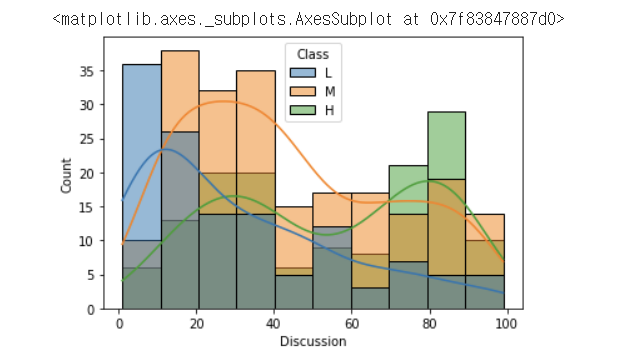
sns.histplot(x='Discussion',data=df,hue='Class',hue_order=['L','M','H'],kde=True)
sns.jointplot(x='VisITedResources',y='raisedhands',data=df,hue='Class',hue_order=['L','M','H'])

sns.pairplot(df,hue='Class',hue_order=['L','M','H'])

### 문제 6. Countplot을 이용하여 범주별 통계 확인하기
# seaborn의 countplot()을 사용
# Hint) x와 hue를 사용하여 범주별 Class 통계 확인
sns.countplot(x="Class",data=df,order=['L','M','H'])

sns.countplot(x='gender',data=df,hue='Class',hue_order=['L','M','H'])

sns.countplot(x='NationalITy',data=df,hue='Class',hue_order=['L','M','H'])
plt.xticks(rotation=90)
plt.show()

sns.countplot(x='ParentAnsweringSurvey',data=df,hue='Class',hue_order=['L','M','H'])

### 문제 7. 범주형 대상 Class 컬럼을 수치로 바꾸어 표현하기
# L, M, H를 숫자로 바꾸어 표현하기 (eg. L: -1, M: 0, H:1)
# Hint) DataFrame의 map() 메소드를 사용
df['Class_value'] = df['Class'].map(dict(L=-1,M=0,H=1))
df.head()

# 숫자로 바꾼 Class_value 컬럼을 이용해 다양한 시각화 수행하기
gb = df.groupby('gender').mean()['Class_value']
gb

plt.bar(gb.index,gb)
plt.xticks(rotation=90)
plt.show()

gb = df.groupby('Topic').mean()['Class_value']
gb

plt.bar(gb.index,gb)
plt.xticks(rotation=90)
plt.show()

gb = df.groupby('Topic').mean()['Class_value'].sort_values()
plt.barh(gb.index,gb)

## Step 3. 모델 학습을 위한 데이터 전처리
### 문제 8. get_dummies()를 이용하여 범주형 데이터 전처리하기
# pd.get_dummies()를 이용해 범주형 데이터를 one-hot 벡터로 변환하기
# Hint) Multicollinearity를 피하기 위해 drop_first=True로 설정
Multicollinearity : 다중공선성(多重共線性)문제(Multicollinearity)는 통계학의 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나는 문제이다. 독립변수들간에 정확한 선형관계가 존재하는 완전공선성의 경우와 독립변수들간에 높은 선형관계가 존재하는 다중공선성으로 구분하기도 한다. 이는 회귀분석의 전제 가정을 위배하는 것이므로 적절한 회귀분석을 위해 해결해야 하는 문제가 된다.
X = pd.get_dummies(df.drop(['ParentschoolSatisfaction','Class','Class_value'],axis=1),
columns=['gender', 'NationalITy', 'PlaceofBirth',
'StageID', 'GradeID', 'SectionID', 'Topic',
'Semester', 'Relation','ParentAnsweringSurvey',
'StudentAbsenceDays'],
drop_first = True)
y = df['Class']
X

### 문제 9. 학습데이터와 테스트데이터 분리하기
from sklearn.model_selection import train_test_split
# train_test_split() 함수로 학습 데이터와 테스트 데이터 분리하기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
## Step 4. Classification 모델 학습하기
### 문제 10. Logistic Regression 모델 생성/학습하기
from sklearn.linear_model import LogisticRegression
# LogisticRegression 모델 생성/학습
model_lr = LogisticRegression(max_iter=10000)
model_lr.fit(X_train,y_train)
### 문제 11. 모델 학습 결과 평가하기
from sklearn.metrics import classification_report
# Predict를 수행하고 classification_report() 결과 출력하기
pred = model_lr.predict(X_test)
print(classification_report(y_test,pred))

### 문제 12. XGBoost 모델 생성/학습하기
from xgboost import XGBClassifier
# XGBClassifier 모델 생성/학습
model_xgb = XGBClassifier()
model_xgb.fit(X_train,y_train)
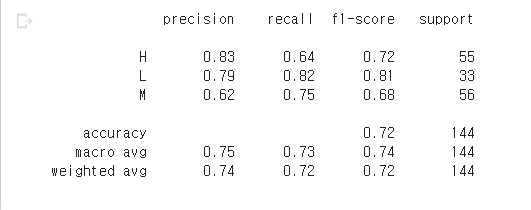
### 문제 13. 모델 학습 결과 평가하기
# Predict를 수행하고 classification_report() 결과 출력하기
pred = model_xgb.predict(X_test)
print(classification_report(y_test,pred))
### Step5 모델 학습 결과 심화 분석하기
### 문제 14. Logistic Regression 모델 계수로 상관성 파악하기
model_lr.classes_

# Logistic Regression 모델의 coef_ 속성을 plot하기
fig = plt.figure(figsize=(15,8))
plt.bar(X.columns, model_lr.coef_[1,:])
plt.xticks(rotation=90)
plt.show()

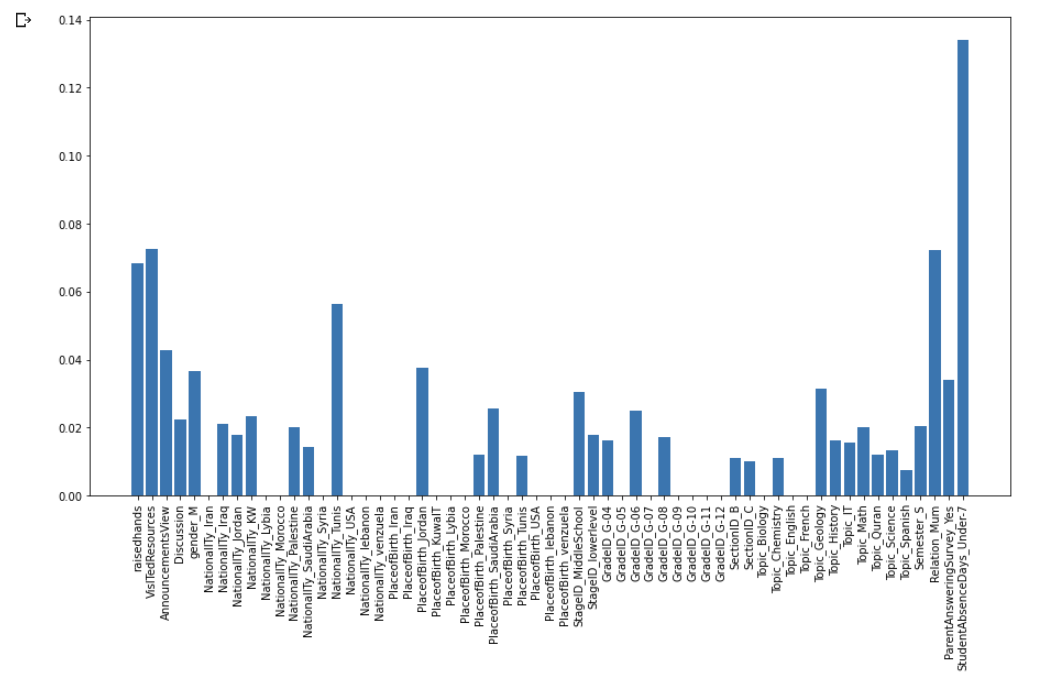
### 문제 15. XGBoost 모델로 특징의 중요도 확인하기
# XGBoost 모델의 feature_importances_ 속성을 plot하기
fig = plt.figure(figsize=(15,8))
plt.bar(X.columns, model_xgb.feature_importances_)
plt.xticks(rotation=90)
plt.show()
'Data Mining with Kaggle' 카테고리의 다른 글
| [로지스틱 회귀분석] league-of-legends-diamond-ranked-games-10-min (0) | 2021.06.25 |
|---|
