# 카카오맵 크롤링
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import time
path = 'chromedriver.exe'
source_url = "https://map.kakao.com/"
driver = webdriver.Chrome(path)
driver.get(source_url)
searchbox = driver.find_element_by_xpath("//input[@id='search.keyword.query']")
searchbox.send_keys("강남역 고깃집")
# 검색 버튼을 눌러서 결과를 가져옵니다.
searchbutton = driver.find_element_by_xpath("//button[@id='search.keyword.submit']")
driver.execute_script("arguments[0].click();",searchbutton)
searchbutton.click()
time.sleep(2)
# 검색 결과의 페이지 소스를 가져옵니다.
html = driver.page_source
# BeautifulSoup을 이용하여 html 정보를 피싱합니다.
soup = BeautifulSoup(html, 'html.parser')
# name='a' : a 태그
# attrs : 속성 설정
# 검색된 맛집의 상세보기 버튼들 : class 속성이 moreview인 a 태그들
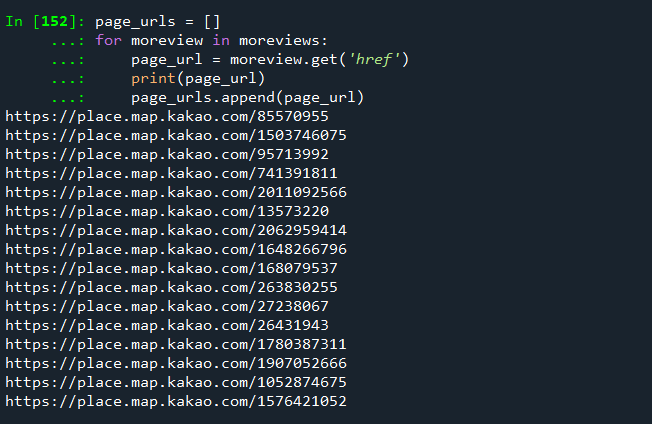
moreviews = soup.find_all(name='a', attrs={"class":'moreview'})
# moreviews a 태그의 href 속성을 리스트로 추출하여,
# 크롤링 할 때 페이지 리스트를 생성합니다.
page_urls = []
for moreview in moreviews:
page_url = moreview.get('href')
print(page_url)
page_urls.append(page_url)
# 크롤링에 사용한 브라우저 종료하기
driver.close()
for p in page_urls:
print(p)
print(len(page_urls)) #16
# 페이지들을 검색하여 정보를 저장하기
columns = ['score','review']
df = pd.DataFrame(columns=columns)
df
driver = webdriver.Chrome(path)
for page in page_urls:
driver.get(page)
time.sleep(2)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 리뷰 크롤링
contents_div = soup.find(name='div',attrs={'class':'evaluation_review'})
# 별점 크롤링
rates = contents_div.find_all(name='em',attrs={'class':'num_rate'})
# 리뷰 크롤링
reviews = contents_div.find_all(name='p',attrs={'class':'txt_comment'})
for rate, review in zip(rates, reviews):
row = [rate.text[0], review.find(name='span').text]
series = pd.Series(row, index=df.columns)
df = df.append(series, ignore_index=True)
for button_num in range(2,6):
try :
another_reviews = driver.find_element_by_xpath("//a[@data-page='"+str(button_num)+"']")
another_reviews.click()
time.sleep(2)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
contents_div = soup.find(name='div', attrs={'class':'evaluation_review'})
rates = contents_div.find_all(name='em',attrs={'class':"num_rate"})
reviews = contents_div.find_all(name='p',attrs={'class':'txt_comment'})
for rate, review in zip(rates,reviews):
row = [rate.text[0],review.find(name="span").text]
series = pd.Series(row, index=df.columns)
df = df.append(series, ignore_index=True)
except :
break
driver.close()
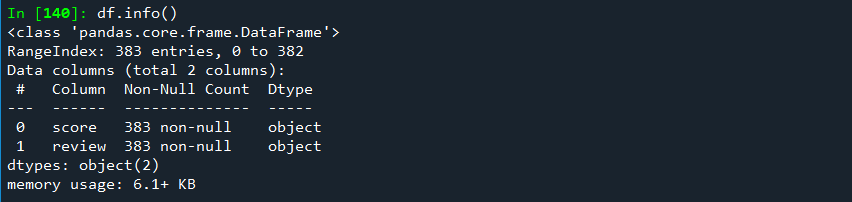
df.head()

df.info()
# df['y'] 추가하기 : score 값이 4 이상이면, 1, 3이하이면 0인 y추가하기
df['y'] = df['score'].apply(lambda x : 1 if float(x) > 3 else 0)
df['y']
df.info()
df.y.value_counts()
df.score.value_counts()
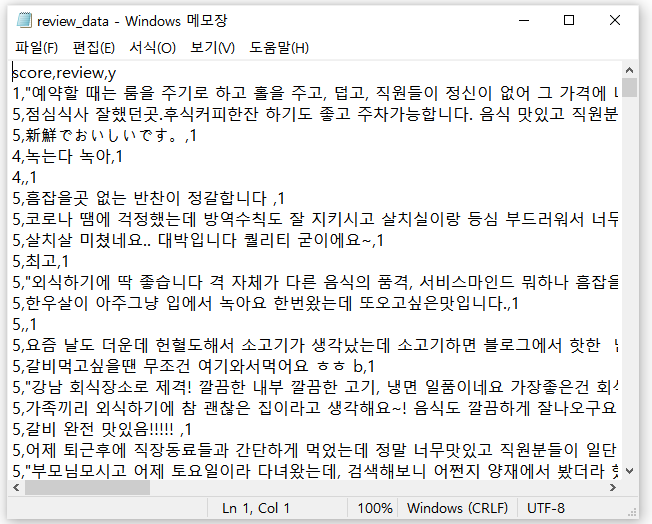
# review_data.csv 파일로 저장하기
df.to_csv("review_data.csv",index=False)
import pandas as pd
df = pd.read_csv("review_data.csv")
df.info()
df.head()
# 한글 외의 글자는 제거하기
import re
def text_cleaning(text):
hangul = re.compile('[^ ㄱ-ㅣ 가-힣]+')
result = hangul.sub('',text)
return result
text_cleaning("abc가나다123 라마사아 123")
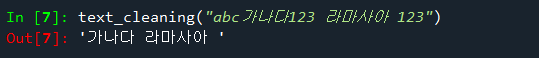
# text_cleaning 함수를 df['review'] 컬럼의 값에 적용을 해서
# 한글 결과는 df['ko_text'] 컬럼에 저장하기
df['ko_text'] = df["review"].apply(lambda x : text_cleaning(str(x)))
# ko_text 컬럼에 한글자 이상의 텍스트를 가지고 있는 데이터만 선택하여
# df 변경하기
df = df[df['ko_text'].str.len() > 0]
df
df.info()
# review 컬럼제거하기
del df['review']
df.info()
# 형태소 단위로 추출
from konlpy.tag import Okt
#konlpy 라이브러리로 텍스트 데이터에서 형태소를 추출
def get_pos(x):
tagger = Okt()
pos = tagger.pos(x)
# word : konply 모듈에 의해서 형태소 분석된 단어.
# tag : konply 모듈에 의해서 형태소 분석된 품사.
pos = ['{0}/{1}'.format(word,tag) for word, tag in pos]
return pos
df['ko_text'].values[0]

result = get_pos(df['ko_text'].values[0])
print(result)

# 분류 모델의 학습 데이터로 학습하기
# 글 뭉치로 변환하기
from sklearn.feature_extraction.text import CountVectorizer
index_vectorizer = CountVectorizer(tokenizer = lambda x : get_pos(x))
# CountVectorizer : 글뭉치(corpus)의 인덱스로 생성하기
X = index_vectorizer.fit_transform(df['ko_text'].tolist())
# 313행
# 2438컬럼(피쳐)
X.shape
for a in X[:3]:
print(a)
print(str(index_vectorizer.vocabulary_)[:100]+"..")
''' 결과
(0, 1594) 1
(0, 2336) 1
(0, 690) 2
(0, 486) 1
(0, 723) 1
(0, 1698) 3
(0, 1992) 1
(0, 718) 1
(0, 2274) 1
(0, 2400) 1
(0, 1990) 2
(0, 575) 1
(0, 2041) 1
(0, 654) 2
(0, 1712) 3
(0, 1927) 1
(0, 1535) 1
(0, 260) 1
(0, 35) 1
(0, 1551) 1
(0, 420) 1
(0, 30) 1
(0, 2043) 1
(0, 222) 1
(0, 839) 1
(0, 83) 1
(0, 677) 1
(0, 1697) 2
(0, 2046) 1
(0, 302) 1
(0, 431) 1
(0, 777) 1
(0, 1520) 1
(0, 1862) 1
(0, 1478) 1
(0, 585) 1
(0, 1930) 1
(0, 1408) 1
(0, 66) 1
(0, 2414) 1
(0, 1692) 1
(0, 2320) 1
(0, 1282) 1
(0, 753) 1
(0, 754) 1
(0, 1354) 1
(0, 1732) 1
(0, 164) 1
(0, 2111) 1
(0, 1799) 1
(0, 2041) 1
(0, 30) 1
(0, 1914) 1
(0, 1842) 1
(0, 2381) 1
(0, 195) 1
(0, 2418) 1
(0, 2171) 1
(0, 2277) 1
(0, 1957) 1
(0, 2002) 1
(0, 46) 1
(0, 1701) 1
(0, 787) 1
(0, 1090) 1
(0, 2163) 1
(0, 1909) 1
(0, 962) 1
(0, 2029) 1
(0, 452) 1
(0, 453) 1
{'예약/Noun': 1594, '할/Verb': 2336, '때/Noun': 690, '는/Josa': 486, '룸/Noun': 723, '을/Josa': 1698, '주기/N..
'''
'''
TF-IDF로 변환
TF : 1개의 텍스트에 맛집 단어가 3번이 있다고 가정. 3값.
IDF : DF의 역산 (inverse)
모든 데이터에서 맛집 단어가 10번이 존재. 0.1 값
TF-IDF : 전체 문서에서 나타나지 않는 값인 경우, 현재 문서에서
많이 나타난다고 가정할 때, 단어가 현재 문서에서 중요한 단어로 판단할 수 있는 값.
'''
from sklearn.feature_extraction.text import TfidfTransformer
Tfidf_vectorizer = TfidfTransformer()
X = Tfidf_vectorizer.fit_transform(X)
print(X.shape)
print(X[0])
# 긍정 부정 리뷰 분류
# 데이터셋 분리
from sklearn.model_selection import train_test_split
y = df['y']
x_train, x_test, y_train, y_test = train_test_split(X,y,test_size=0.30)
# 학습데이터 크기
x_train.shape
# 테스트데이터 크기
x_test.shape
# Logistic Regression 모델을 이용하여 분류하기
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(random_state=0)
lr.fit(x_train, y_train)
y_pred = lr.predict(x_test)
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
#로지스틱 회귀 모델의 성능 평가
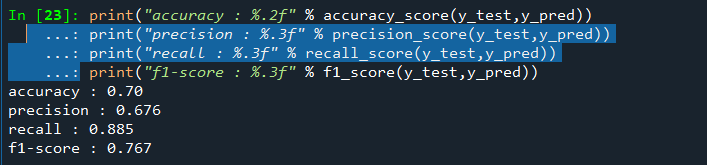
print("accuracy : %.2f" % accuracy_score(y_test,y_pred))
print("precision : %.3f" % precision_score(y_test,y_pred))
print("recall : %.3f" % recall_score(y_test,y_pred))
print("f1-score : %.3f" % f1_score(y_test,y_pred))
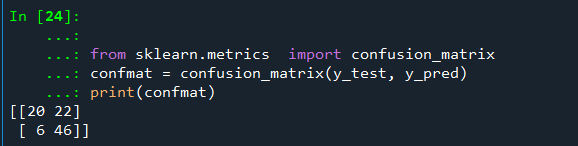
#혼동행렬 출력하기
from sklearn.metrics import confusion_matrix
confmat = confusion_matrix(y_test, y_pred)
print(confmat)
'''
[[ 3 36]
[ 1 54]]
0 1 => 예
N P
0 F [TN] [FP]
1 T [FN] [TP]
TP : 실제 T 예측 P 진짜 Positive 54
TN : 실제 F 예측 N 진짜 Negative 3
FP : 실제 F 예측 T 가짜 Positive 36
FN : 실제 T 예측 F 가짜 Negative 1
특이도 (Specificity) : 모델이 False로 예측한 정답 중 실제 False
'''
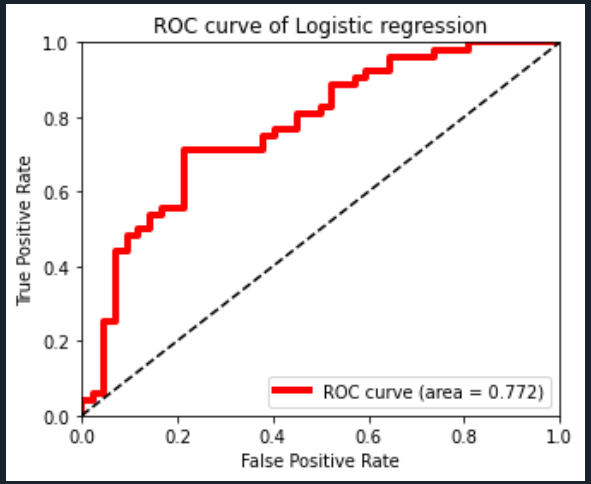
# ROC 곡선
# TPR (True Positive Rate) : 진짜 양성 비율 민감도
# FPR (False Positive Rate) : 가짜 양성율 1-특
# AUC (Area Under the Curve) : 곡선의 아래 면적
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt
y_pred_probability = lr.predict_proba(x_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_pred_probability)
roc_auc = roc_auc_score(y_test, y_pred_probability)
print("AUC : %3.f" % roc_auc)
# false positive rate : FPR = 1- 특이도
# true positive rate : TPR = 민감도
plt.rcParams['figure.figsize'] = [5,4]
plt.plot(false_positive_rate,true_positive_rate,
label='ROC curve (area = %0.3f)' % roc_auc,
color = 'red', linewidth=4.0)
plt.plot([0,1],[0,1],'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve of Logistic regression')
plt.legend(loc='lower right')
'Python' 카테고리의 다른 글
| 파이썬 (map, filter, reduce, lambda) (0) | 2023.06.25 |
|---|---|
| 파이썬, 함수형 프로그래밍 (일급 함수) (0) | 2023.06.25 |
| Python - 홈페이지 탐색(with Selenium) (0) | 2021.07.23 |
| Python - 시계열분석(TimeSeries) (0) | 2021.07.21 |
| Python - 군집분석 (0) | 2021.07.20 |

