정렬 : 주어진 기준에 따라 데이터를 크기 순으로 재배열하는 과정
- 숫자의 경우는 숫자의 크기에 따라 정렬이 가능
- 문자열의 경우는 알파벳순 또는 가나다순으로 정렬이 가능
1. sort() : 값의 크기에 따라 값들을 정렬
# 정렬(sort)
v1 <- c(1,7,6,8,4,2,3)
v1
#오름차순
v1 <- sort(v1)
v1
결과값 : 1 2 3 4 6 7 8
#내림차순
v2 <- sort(v1, decreasing = T)
v2
결과값 : 8 7 6 4 3 2 1
#문자 정렬
name <- c('정대일','강재구','신현석','홍길동')
#오름차순
name <- sort(name)
name
결과값 : "강재구" "신현석" "정대일" "홍길동"
#내림차순
name2 <- sort(name, decreasing = T)
name2
결과값 : "홍길동" "정대일" "신현석" "강재구"
2. order() : 값의 크기에 따라 인덱스를 정렬
name <- c('정대일','강재구','신현석','홍길동')
#오름차순
order(name)
결과값 : 2 3 1 4 (강재구,신현석,정대일,홍길동 순으로)
#내림차순
order(name, decreasing = T)
결과값 : 4 1 3 2
3. 매트릭스와 데이터프레임의 정렬
#특정 열의 값들을 기준으로 행을 재배치
#iris 데이터 셋의 Sepal.Length 기준으로 행을 재정렬하기
head(iris)
order(iris$Sepal.Length)
# 오름차순으로 정렬
iris[order(iris$Sepal.Length),]
# 내림차순으로 정렬
iris[order(iris$Sepal.Length, decreasing = T),]
#carData 데이터로 정렬 연습하기
.libPaths("C:/User/Rstudy/20210513")
getwd()
library(carData)
str(Highway1)
# 일일 교통량(adt)이 적은 하위 10개 구간의 일일 교통량(adt), 사고율(rate)을 알아봅니다.
tmp <- Highway1[order(Highway1$adt),c('adt','rate')]
tmp
tmp[1:10,]

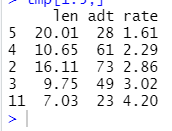
# 제한속도(slim)가 높은 상위 5개 구간의 길이(len), 일일 교통량(adt), 사고율(rate) 을 알아봅니다.
tmp <- Highway1[order(Highway1$slim,decreasing = T),c('len','adt','rate')]
tmp[1:5,]
'R' 카테고리의 다른 글
| R - 조합, 집계 (0) | 2021.05.31 |
|---|---|
| R - 샘플링(sampling) (0) | 2021.05.31 |
| R - 결측값 처리 (0) | 2021.05.28 |
| R - attach/detach 함수 (0) | 2021.05.28 |
| R - 산점도(scatter plot) (0) | 2021.05.27 |



