샘플링 : 데이터가 너무 큰 경우 분석 시간이 많이 걸릴때, 일부의 데이터만 추출하여 대략의 결과를 미리 확인할수 있다.
1) 비복원 추출 : 한번 선택된 데이터는 제외
2) 복원 추출 : 한번 선택된 데이터 포함
#복원 추출
x <- 1:100
y <- sample(x,size=10,replace=TRUE)
y

#비복원 추출
x <- 1:100
y <- sample(x,size=10,replace=FALSE)
y

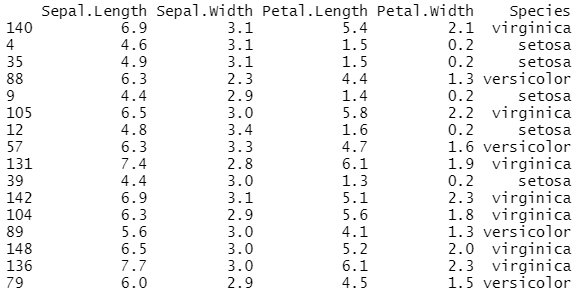
# iris 데이터에서 50개를 임의로 추출하여 idx 데이터에 저장하기
idx <- sample(1:nrow(iris),size=50,replace=F)
idx #50개 임의의 행의 번호
iris50 <- iris[idx,]
iris50
#set.seed() : 샘플링시 유추할 수 있는 데이터 값 필요한 경우 / 샘플링 값 고정 / sample 실행전마다 반복 실행해야 됨
set.seed(100)
sample(1:20,size=5)

# carData 패키지에 KosteckiDillon 데이터를 이용한 연습
str(KosteckiDillon)
# 전체 데이터의 평균 치료일수(dos) 조회하기
mean.dos <- mean(KosteckiDillon$dos)
mean.dos
# 전체 관측값의 10%, 20%, 30%, 40%, 50%를 샘플링 했을 때 평균 치료일수의 평균을 전체 평균과 비교하기
for(rate in (1:5)*0.1){
set.seed(100)
idx <- sample(nrow(KosteckiDillon),nrow(KosteckiDillon)*rate)
sam.data <- KosteckiDillon[idx,'dos']
tmp.mean <- mean(sam.data)
cat('전체 평균 :',mean.dos,'샘플링 비율:',rate,'샘플링 평균:',tmp.mean,
'차이 :',mean.dos-tmp.mean,'\n')
}
* nrow(KosteckiDillon) : 행의 수
* nrow(KosteckiDillon)*rate : 샘플링 갯수
* mean(sam.data) 평균 치료일수의 평균

'R' 카테고리의 다른 글
| R - treemap (나무지도) (0) | 2021.06.01 |
|---|---|
| R - 조합, 집계 (0) | 2021.05.31 |
| R - 정렬 (sort, order) (0) | 2021.05.31 |
| R - 결측값 처리 (0) | 2021.05.28 |
| R - attach/detach 함수 (0) | 2021.05.28 |



